
2013
6th Jan 2013 Familiarity and Novelty
Carrying on from the 21st Dec 2012 I have the answer to the problem. I was thinking about the edge combinations not being formed between two very high level familiar parts and how they may occur very frequently but they never form patterns worth re-identifying until the two high level parts start occurring together. Then the edge combination starts to reoccur frequently. The answer is to use the rule that "two source binons must be familiar before a novel target is formed from them". And to apply this rule between the shape and property binons to form the object binon and between the object binon and class label binon to form the associating binon.
10th Jan 2013 Gaps
If we have dependent sensors but all the sensors are treated as independent then the process of creating all possible pairs at level 2 not only creates the adjacent ones (dependent sensors) but also the ones with gaps. Then the process of combining pairs that include overlaps (aggregation) produces all the dependent sensor combinations but also all the ones with gaps in them. This approach avoids creating any combinations with gaps at the ends because only non-gap parts are used in the aggregation process. So dependent sensors can be treated as independent sensors with the addition of gaps and the pairs are ordered.
Representing gaps
But the pairs with a gap must be represented appropriately so they can be re-identified when the parts are closer, bigger and the gap is also bigger. Pairs with no gap (adjacent) also have a gap but its size is zero. Now the representation for the object and gap becomes more complicated. The shape of each pair of parts = sensor groups (a group is adjacent sensors all with the same reading within the JND) must be represented as before with a shape pattern = ratio but the gap must also be represented. For adjacent parts the gap is zero and non-zero otherwise.
Grouping
The Gestalt fact that we visually group together similar objects that are closer to each other before those that are farther away seems to imply that the process of forming a sensor group first before forming pairs is not what our vision does. It would seem it processes sensors based on how far they are apart rather than the level of complexity.
If one uses this grouping approach and applies the right principles for aggregating, forming edges and patterns the following sensor readings get processed as shown. At each span (number of sensors involved) the top line is the contrast pattern / reading, the middle the type of object (S = Sensor, P = Part, E = Edge) and the third line is the shape pattern / size (quantity of sensors)
Span 1 1 4 3 1 1 1 4 4 3 3 1
1 S S S S S S S S S S S S
1 1 1 1 1 1 1 1 1 1 1 1
↓ ↓ \ / ↓ \ / ↓ \ / ↓ ↓ ↓ \ / ↓ ↓ \ / ↓ ↓ \ / ↓
Span 1 1 1/4 4 4/3 3 3/1 1 1 1 1/4 4 4 4/3 3 3 3/1 1
1.5 S S E S E S E S S S E S S E S S E S
1 1 1 1 1 1 1 1 1 1 1 1
\ / ↓ ↓ ↓ ↓ ↓ \ / \ / ↓ \ / ↓ \ / ↓ ↓
Span 11 1/4 4 4/3 3 3/1 11 11 1/4 44 4/3 33 3/1 1
2 S E P E P E S S E S E S E P
2 1 1 2 2 2 2 1
↓ ↓ ↓ \ / ↓ ↓ \ / ↓ ↓ ↓ ↓ ↓ ↓
11 1/4 4 4/3 3 3/1 111 1/4 44 4/3 33 3/1 1
3 P E P P P E S E P E P E P
2 1 1/1 1 3 2 2 1
\ / ↓ ↓ ↓ ↓ ↓ ↓ \ / \ /
1/4 4/3 3 3/1 111 1/4 44 4/3 3/1
4 P P P E P E P P P
2/1 1/1 1 3 2 2/2 2/1
\ / ↓ \ / \ / ↓ \ /
1/4/3 4/3 3/1 1/4 4/3 4/3/1
5 P P P P P P
2/1/1 1/1 1/3 3/2 2/2 2/2/1
↓ \ / \ / \ / ↓
1/4/3 4/3/1 3/1/4 1/4/3 4/3/1
6 P P P P P
2/1/1 1/1/3 1/3/2 3/2/2 2/2/1
By looking at this example the rules for transforming one span level to the next are:
Start by placing edges between any two sensors that are adjacent with a different value to generate level 1.5
If any two sensors are adjacent and the same value, generate the combined sensor with a size one greater.
Any sensor with an edge on both sides gets transferred as a Part of the same size
Any two parts that are the same level of shape complexity separated by an edge or not get combined by aggregation. The edge is removed. The parts not combined on both sides get transferred to the next span level. Any edge not removed gets transferred.
11th Jan 2013 Gaps
To be more consistent with my current levels of complexity the span levels should start at 0 for the sensor only level and then be 1 for the level in which a single sensor detects a part of width 1.
But to completely represent shapes and contrast objects it looks like an object needs parts to represent the concepts of shape pattern, gap part, contrast pattern and quantity of similar parts (pattern?). The contrast pattern must be a null object if a non-zero gap is involved. The gap and contrast patterns are mutually exclusive. As soon as there is a gap the contrast pattern does not exist between the two non-adjacent parts. A gap object is only needed at level 2 when two parts are not adjacent. A contrast object is only needed at level 2 when two parts are adjacent. And I have theorised previously that I should not be forming contrast objects of level of complexity 3 or higher. The jury is still out on the need for level 3 or higher contrast patterns.
Jan 26th 2013 LinkedIn Discussion
Boris has done a fine job of summarizing the 1st Hebbian rule. But there is a second one. I'm quoting from the book "Cortex and Mind" written by Dr. Joaquin Fuster on page 42 he writes: "In addition to the temporal coincidence or correlation of pre- and postsynaptic firing, there is another condition (Hebb's second rule) leading to synaptic facilitation; this condition is the temporal coincidence of presynaptic inputs arriving to the same cell or to different cells of the same assembly. Hebb also envisioned the importance of this condition for memory network formation. He wrote, “any two cells or systems of cells that are repeatedly active at the same time will tend to become 'associated,' so that activity in one facilitates activity in the other. ... [Here] I am proposing ... a possible basis of association of two afferent [input] fibers of the same order - in principle, a sensori-sensory association"
Or in plain English if two source neurons fire at the same time onto a target neuron then the association between the two source neurons is strengthened. The two source neurons effectively are "joined" / associated / "wired up" via the same target neuron. Thus you often hear Hebb's rules summarized in the statement: "Cells that fire together, wire together".
28th Jan 2013 Action Learning
Hebb's 1st rule for forming associations will help in the learning of actions. The objective is to learn a source acton that stimulates / starts two target actons in parallel or sequence. The activation is going down the hierarchy to the action devices. The source acton is added to represent the combination of the two target actons when they are started in parallel or in sequence. Effectively the post-synaptic stimulus has occurred before the pre-synaptic stimulus. It's like learning combinations of post-synaptic stimuli. So the two target actons need to be learnt / familiar and started before the existence of the source acton. Then the source acton is created to represent the combined action as a single action. The lowest level target actons must be the ones that the reflexes use, the atomic device instructions / responses.
Quantity
Quantity is a level of measurement called count. It has no units. It is not symbolic because it has order. It is always a measure of a part / object that has been recognized. It is best represented as a level 1 binon that contains the integer value of the logarithm of the count.
Jan 29th 2013 LinkedIn discussion
I believe that we store knowledge of what we experience in the form of "class prototypes". These are effectively aggregations of patterns of property values. Visual examples of such patterns are shape and contrast patterns. We don't store the property values that are used to form these patterns. We just keep the patterns. The property values are size and intensity. The patterns are the relationships between such property values. For example a shape of 2/1/7 is formed from the relationships between adjacent sizes of 2, 1 and 7. The shape pattern 2/1/7 is position independent and size independent because a shape that is 4/2/14 is the same class of object possibly in a different position but just closer to you, thus bigger. These are what the latest Scientific American article is calling Concept Cells. They are abstract representations that can be recognized again when given a set of property values. These are what we imagine is behind us without looking around. These are what we aggregate to form our internal mental model of the world. These are what we recall and think about.
29th Jan 2013 Grouping
Carrying on from the 10th Jan I should really be using quantity instead of size for sensors that are adjacent and reading the same intensity. For the first two sensors of the readings 114311143431 I should be forming the 11 binon as the aggregation of a quantity-2 binon with an intensity-1 binon. The level of complexity in my activation tree should correspond to span of sensors. The 4 should be formed as the aggregation of a quantity-1 binon with an intensity-4 binon. The 14 should be a shape binon as an aggregation of the two quantity & intensity binons. The 111 must end up as a quantity-3 binon with an intensity-1 binon. The new activation tree would look like:
At each span (number of sensors involved) the top line is the Intensity / contrast pattern, the middle line the type of object (G = Gap, Q = Quantity, S = Shape pattern, I = Intensity, C= Contrast pattern) and the third line is the value combination.
I started with this structure:
Span 1 1 4 3 1 1 1 4 3 4 3 1
1Q 1 1 1 1 1 1 1 1 1 1 1 1
1 I 1 1 4 3 1 1 1 4 3 4 3 1
\ / \ / \ / \ / \ / \ / \ / \ / \ / \ / \ /
Span 11 14 43 31 11 11 14 43 34 43 31
Gaps are all zero
2Q 2 1 1 1 2 2 1 1 1 1 1
2 I 1 1 1
2S 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1 1/1
2C 1/4 4/3 3/1 1/4 4/3 3/4 4/3 3/1
Repeaters \ /
2Q 2
2S 1/1
2C 4/3
2G 2 2 2 2 2
\ / \ / \ / \ / \ / \ / \ / \ / \ / \ /
Span 114 143 431 311 111 114 143 434 343 431
3Q 1 1 1 1 3 1 1 1 1 1
3 I 1
3S 2/1 111 111 1/2 111 2/1 111 111 111 111
3C 1/4 143 431 3/1 1/4 143 434 343 431
Then I started cleaning it out:
Span 1 1 4 3 1 1 1 4 3 4 3 1
1Q 1 1 1 1 1 1 1 1 1 1 1 1
1 I 1 1 4 3 1 1 1 4 3 4 3 1
1G 1 1 1 1 1 1 1
\ / \ / \ / \ / \ / \ / \ / \ / \ / \ / \ /
Span 11 14 43 31 11 11 14 43 34 43 31
Gaps are all zero - only adjacents processed
2Q 2 1 2 2 1 1 1 1
2 I 1 1 1
2S 1/1 1/1 1/1 1/1
2C 4/3 4/3 3/4 4/3
Repeaters \ /
2Q 2
2S 1/1
2C 4/3
Gaps created
2G 2 4 2
\ / \ / \ / \ / \ / \ / \ / \ / \ / \ /
Span 114 143 431 311 111 114 143 434 343 431
3Q 1 3
3 I 1
3S 2/1
3C 1/4
3G 3
\ / \ / \ / \ / \ / \ / \ / \ / \ /
Span 1143 1431 4311 3111 1114 1143 1434 4343 3431
4Q 1 1 1 1 1 1 1 1 1
4 I
4S 211 1111 112 1/3 3/1 211 1111 1111 1111
4C 143 1431 431 3/1 1/4 143 1434 4343 3431
But I gave up at this point.
1st February 2013 Grouping
I think I should go back to the structure from 10th Jan 2013 but not include the edges as things but just use the idea that if there is an edge on both sides of a part then it is a candidate for aggregating with an adjacent part.
Gaps
I think it is not possible to form gaps until the two separate parts (separated by a gap) move in unison. Only then do the two separate parts have a common property (motion) that causes them to be grouped. This is Gestalt common fate. This needs the time dimension. But I also want to use the gaps to form patterns that provide for independence of complexity. Is it possible to do this without introducing the time dimension? The comment from 14th Dec 2012 is very relevant. The shape pattern formed from two gaps has to already exist as a shape composed of non-gap parts before the shape formed from gaps can be recognized. Therefore one does not form novel shapes out of gaps. But adjacent gaps are checked for the existence of their shape. So gaps are level-1 / sensor level things that exist in the activation tree and only as a level-1 binon with a quantity = size. A pattern of gaps exists in the activation tree as a shape at a higher level.
Contrast
The contrast pattern is tough to get rid of. If I have a repeating pattern such as 435743574357 the pattern of contrast must be formed to identify the 4357 repeater and so a change can be noticed such as 435743474357.
Purpose
Currently I form a new combination of patterns if the two source patterns are familiar. But I need a stronger motivation / reason to do this. Why do we form them in the first place? Obviously so we can recognize it again if we encounter it. May be the idea is to only combine the familiar patterns if they are coincidental and they both have been "useful". Useful because they have contributed to the correct identification of the experience. But if all new ones get class labels then every familiar one has an associated class label. Maybe the two source patterns have to be familiar and associated with the same class label.
2nd February 2013 Purpose
The binons / patterns that are useless are the ones that are ambiguous. The ones that only have one class label are useful. Therefore I should only combine familiar ambiguous binons. If I have two familiar ones, the first is ambiguous (two or more class labels) and the second is not (only one class label) then don't combine them. The second identifies the class of object. If it is wrong it will have a second class label associated with it and it will become ambiguous and combined next time the same class of object is experienced.
3rd Feb 2013 Similarity vs. Proximity
The Gestalt laws of Proximity and Similarity tend to be working hand in hand. It starts with immediately adjacent then the same. Then just a little apart and then the same. And so on further apart and then the same. And not just the same but also similar in that they contain the same sub part. The process must group the closest things first and merge those that are the same. Then it must repeat this for things just a little further apart etc.
Similar intensity and similar size are competing against each other with proximity being used first. For patterns similar shapes and contrasts are competing to be grouped. Two objects at the same distance apart with the same shape and same contrast win over two objects with the same shape but different contrast or two objects with different shapes but the same contrast.
4th Feb 2013 Similarity vs. Proximity
In order to group two parts (level-1 objects with intensity and width) that are the same and separated by a gap we must include the gap in the grouping. If the two same parts are adjacent the gap is zero. Maybe a gap of width zero is an edge and all edges should be gaps of zero width.
The idea that intensity / brightness / volume is local and I should not form patterns from it has some evidence in the facts that parts of an object that are separated are usually made from the same material, same colour and most likely under the same illumination. So I should be using intensity in order to associate separated parts rather than forming patterns of it. Or whatever patterns I do form they should be over very small distances. But I have pointed out that I need the contrast pattern to help identify repeating patterns. Or do I? Maybe repetition of shape is sufficient. The eye seems to abuse intensity gradient in order to enhance edges. That is another piece of evidence that it is of less importance. Intensity gradient / contrast patterns seem to be local within a shape.
The following grouping algorithm uses a “+” sign to mean there is a used edge and a “-“ sign for a need to use edge. A minus wherever it is not shown. The y says can be used to form an object, x says it has the same part of one side or the other and therefore repeats. V means combine and | carry forward because it has not been combined on it's “-" side. Quantity is in brackets e.g. (3). The second row of numbers contains size patterns.
+1- -9- -1- -1- -1- -4- -3- -4- -3- -5- -7- -5- -2- -2- -3- -2- -2+
y y x x x y y y y y y y x x y x x
V ↓ V V ↓ V V V V V V ↓ V ↓ V
+19- +9- -1(2)- -1(2)- -4+ 43 34 43 35 57 75 +5- -2(2)- -3- -2(2)+
↓ ↓ V V V ↓ V V V
+19- +9- -1(3)- 43(2) -575 75- 52 23 32+
11 1 3 11 111 11 12 21 12
↓ V ↓ V V V
+19- -91- -575- 752 523 232
11 13 111 112 121 212
V V V V
191 5752 7523 5232
113 1112 1121 1212
The question is what to do with the repeated 43 in the middle.
1st March 2013 Two-dimensional pattern classification
Back on 22nd Nov 2012 I started thinking about two dimensional sensor arrays and pattern recognition. I've been thinking about it more recently as I have been writing my paper for ICCM. My initial idea based only black and white images was to form the following 8 patterns and combinations of horizontal and vertical 2 pixel pairs.
1. ░ ░ 2. ░ ░
░ ▓
3. ▓ ▓ 4. ▓ ▓
▓ ░
5. ▓ ░ 6. ░ ▓
░ ▓
7. ▓ ░ 8. ░ ▓
▓ ░
But on further thought I felt I should be using some sort of blob or area as the most primitive object equivalent to the lines in one dimension. So I thought of using a square that can be one pixel in size or larger. I only need one number to represent its size and then two squares adjacent to each other would have a relative size ratio. But when you divide up a 4 by 5 rectangle into squares you get a 4 by 4 square and 4 1x1 squares beside it. A 4 by 6 rectangle divides into a 4x4 square and 2 2x2 squares beside it. A 4 x 7 rectangle divides into a 4x4 square; a 3x3 square and 3 1x1 squares. This seems two complex, especially when it comes to representing rectangles of more subtle size difference such as 100 x 103 which has be seen as a 100 x 100 when considering Weber's just noticeable difference.
So I am now thinking the basic object is a rectangle with a height and width ratio. These would be the level 2 shape objects. Then when two rectangles are adjacent a more complex shape is formed. Except this combination needs information about where the two rectangles are attached to each other to make the shape re-identifiable. This must be based on how far down the side the second rectangle is attached to the first.
Each rectangle will have a height and width. Given each rectangle all the horizontal pairs will be generated and all the vertical pairs will be generated at level 3. There may be more than 1 rectangle on the right side and on the bottom side thus the reason for "all" in the previous sentence. Each pair also must be associated with a ratio for how far down the second one is. This will be a ratio fraction greater than 0 and up to 1. For example when two rectangles are horizontally adjacent the positions of the top left pixel in the second rectangle will align somewhere between pixel #1 down to the pixel #H (height) on the right side of the first rectangle. If it aligns with the top edge of the 1st rectangle the ratio will be 1/H where H is the height of the 1st rectangle. If it aligns with the last pixel on the right side of the 1st rectangle then the ratio will be H/H. The same process will apply to two rectangles vertically adjacent. This will result in pairs which need to be combined / aggregated as described in the 1st paragraph today.
A key problem occurs when the 2nd rectangle on the right extends its top edge above the 1st rectangle's top edge. All the possible pairs are formed by all the possible adjacent edges on the rectangles with a uniform intensity within them. The best way to form all these pairs is to find each rectangle and form all the pairs on its right and bottom side. Then go on to the next rectangle. But still have a problem representing 3 adjacent rectangles such that any two in the threesome can match any two in some other threesome. I have to think about this.
9th March 2013 Perceptra 2D
I have tried combining the adjacent triangles with the same intensity reading into unique shapes and using those for recognition. This does not work because the chances of the exact shape occurring again are very slim, even if it is independent of position size and intensity. So I went back to just rectangles as the primitive level 1 parts. I then made patterns from adjacent rectangles to the right, below, attached on the corner to the bottom right and on the corner to the bottom left with the same intensity reading. This works really well with an 80% prediction success rate on the 8x8 hand drawn digit bitmaps. It also works well with the images that contain all the 16 levels of brightness.
Edges
I had a thought that edges are the simplest parts and I should use these at level 1. Each edge would be a contrast property binon at level 1 containing the intensity ratio from either side of the edge. The width property would be all the same level 1 shape binons and the activation tree would contain the edge's sensor position. Then at level 2 all the adjacent two edge contrast binons would be aggregated and the distance between them put in the activation tree with the generic gap binon. Then at level 3 contrast binons would represent 3 edges and width binons would finally contain the width ratios to represent shapes composed of two adjacent widths.
15th March 2013 Logarithms
I contend that the use of logarithms is only needed at the sensory level for properties that range over many orders of magnitude. Within the binon network only addition (aggregation) and subtraction (ratios) are needed / taking place.
23rd March 2013 Sequence Labelling
I'm starting to work on sequential (temporal / time) classification and wanted to summarise some key principles / ideas I have accumulated.
- Whenever the word “change” is being used, time is involved.
- Any two patterns, parts or edges that change in unison at the same time by the same amount / same velocity belong to the same object. This is co-incidence of motion / change.
- As an object changes, possibly due to rotation, some of the relationships / patterns between its parts stay the same. New parts may appear and existing parts may disappear. However some subset of the object remains un-obscured, un-occluded, or unobstructed. The remaining parts may expand, contract, change intensity or position (move) but not the relationships / patterns.
- The purpose is to pay attention to novelty, interesting things that happen. This is a subset of the scene. Relationships that stay the same repeat. Repetition is boring. Repetition is expected, recognized and inhibited (19th July 2012)? Thus, form new patterns from the unexpected parts, but provided these parts are familiar. Otherwise you have new parts and they are not combined until they become familiar.
- A STM is required on each independent sense and / or sensor to detect repetition and novelty. But dependent sensors must be processed before independent sensors / dimensions or senses.
- Time is a measured graduated quantity like sensor position. Duration is equivalent to width and patterns of time are based on relative duration (ratios). These are determined based on Weber-Fechner logarithms. The IDL (Integer Difference of the Logs) must be used.
- Ganglion neurons in the retina exist for intensity but also for decreasing and increasing intensity. Thus the change in intensity is a reading coming from the sensors.
- If the sense is graduated but does not span many orders of magnitude, such as angle of rotation, logarithms are not used in the increase and decrease in the value. When dealing with PID (Proportional-Integral-Differential) controllers this increase or decrease in value is called the error. It is the difference between the actual point and the set point (desired / goal). If these errors / changes are stored in level 1 binons then the binon network (aggregation lattice) represents the recognition of possible PID combinations.
24th March 2013 Temporal pattern recognition
So now given a linear array of 4 graduated sensors with the following readings 7, 4, 7 and 7 consider a change to 7, 7, 4 and 7. The edges were -/7, 7/4, 4/7 and 7/-. They will stay the same edges except the positions of the 7/4 and 4/7 edges have moved over one sensor. The values of sensor #2 and #3 have changed. Sensor #2 has increased from 4 to 7 and sensor #3 has decreased from 7 to 4. From an object perspective the width of the left object of reading 7 has expanded from one sensor to two and the width of the right object of reading 7 has contracted from two sensors to one.
According to idea seven above it would be the increase / decrease in reading that is the true source of information to be processed. This is also consistent with the idea of a PID controller in which there is only one sensor - change in position or width is not possible with only one sensor. Then according to idea four above attention is drawn to those sensors that change. They are the ones processed for recognition purposes. Since we are dealing with time we will assume that any two sequential frames are one unit of time apart. Thus we are dealing with a change per unit time. These are rates of change of intensity, position (velocity) or width (expansion / contraction) etc. The motion and expansion / contraction experiences though are the result of the interpretation of the change in intensities of the sensors. In fact to represent the concept of motion, the aggregation of feedback stimuli from the eye muscles when they track the moving object may be required.
Now applying idea two to the change of the sensor readings it would seem logical to combine / aggregate those sensors that changed in unison, that is, by the same amount. The change in intensity is an edge in time. As an edge it should be represented as the ratio of the before and after readings. Edges in position at level 1 were combined successfully to create widths at level 2 that were then combined to produce the lowest level shape patterns (width ratios) at level 3. If this approach were used for edges in time then the duration between two changes in intensity for a sensor would be durations. Then two durations would produce a ratio pattern that could be re-identified. This then gets back to recognizing objects in a 2D array of sensors.
2D Shapes
When recognizing 2D shapes I have taken two approaches. First, breaking up an area with the same intensity into adjacent rectangles that go as far left and right and up and down as possible. Then doing the same for the remaining area with the same intensity. This ends up with the minimum number of adjacent and largest rectangles to cover the area. The second approach used edges to determine the extent of the rectangles. Given any one edge of the rectangles formed it had to have the same edge pattern along the extent of its side. This resulted in a lot more, smaller adjacent rectangles to cover the area.
A third approach that could be based on the use of the edges is one in which the rectangles overlap. They go as far as they can in both directions until they come up against an edge. Would this make the aggregation of the rectangles simpler because they must share at least one sensor position? My preliminary analysis says it will produce the same quantity or slightly more of the rectangles as in the first approach. It also appears the same rectangles will be produced when one of the dimensions is time. A linear array of sensor readings is sequentially added and the process can do this with all the layers available in parallel or over time.
28th March 2013 Spreading activation
The temporal / sequential 2D algorithm is equivalent to a spreading activation process that starts at every location in the 2D space and ends up being a minimal set of overlapping rectangles that covers the space.
8th April 2013 Rectangles
I have the third approach working. Any two rectangles are combined if they overlap which means they both have the same reading. Also any two rectangles that are attached at corners are combined provided they have the same reading. When two rectangles are combined the combination retains the relative size (horizontal width ratio) of the two parts plus the gap / offset of the top left pixels in the two rectangles to maintain their relative positions. Three rectangles get combined provided they share a common rectangle and no binon values are required at this level or higher. This ends up with areas that have the same reading. But two areas with different readings are not combined. What are the criteria for this combination?
A pair of overlapping rectangles with the same reading is no longer a rectangular shape and could have many edges adjacent to rectangles with different readings. Do I take the upper, lower, left and right extents of the pair as its new area, a new rectangular area? Then do I use it as a rectangle that may be adjacent or overlap with another rectangular area with a different reading? Or do I combine the lowest level original rectangles that are adjacent and have different readings into pairs and then combine these pairs based on common parts?
10th April 2013 Slower learning
Currently a novel binon is only formed from two familiar source binons in unsupervised learning mode. This means they have to occur co-incidentally and they have to be already learned - experienced once before since they become neutral on their second occurrence. What instead they have to be boring before being combined. That means they have to have been experienced at least twice before. Would the level of interest I'm calling boring be a perceptual equivalent to the behavioural interest of permanent?
But then there is the concept of unique versus ambiguous. If a binon is part of two or more target binons then it is ambiguous - used as part of two or more higher level more specific types of things. It always has to be familiar before it can be combined and then become ambiguous. The objective is to pursue novelty and avoid boredom / repetition. But that is the objective for behaviour. What is the objective for perception? It is the need to identify / recognize things uniquely. Thus can we also wait for them to become ambiguous before combining them? No, can't do this because they will never be combined. Familiarity of the source binons is necessary.
11th April 2013 To Do List
I have got the 1D and 2D single-sense pattern recognition working for graduated stimuli. And I have 1 sense, 1 sensor, and symbolic, sequential recognition working in Scriptra. Now the next thing to do is to get the single sense, 1 sensor, and graduated, sequential recognition working. Morse code would be an ideal test for this. Then I could get 1 sense with multiple sensor graduated sequential recognition working. This would be speech recognition. I could go on to 2D visual sequential recognition, but by this time it would be better to go on with motor control for a single muscle / device.
12th April 2013 The border
While getting the 6000 digits to be recognized in 2D I have realized that the border of the visual area is an artificial edge and should not be used to form rectangles in the pattern recognition. Thus when attention is paid to a particular rectangular area the border of this area should play no part in the formation of the types of parts recognized.
14th April 2013 Fewer Binons
I must try the strategy of not creating any more new binons as soon as I find or create the first unambiguous binon. The creation of new binons would be very slow but if many frames of experience occur per second it would not take long to create many new ones.
Contrast improvement
I have recently removed the contrast pattern formation from Perceptra but maybe that was a mistake. For recognizing kinesthetic sensory input over time to control muscles as in a PID controller, the binon network must integrate and differentiate a sequence of stimuli readings. This is a contrast pattern in the time dimension. It is actually using the error stimulus (difference between goal and actual "position") for this purpose. The range of errors does not extend over orders of magnitude so logarithms do not need to be taken before calculating the difference. So maybe for contrast patterns I should avoid the logarithms and just subtract the intensities that the computer uses for brightness. These are also not over orders of magnitudes; they range from 0 to 255.
Contrast patterns allow us to determine the breadth of a contour. So, it also may be that I have to calculate change in intensity per distance (number of sensors). Take for instance the sensor intensity values of 0, 0, 0, 155, 255, 255, 255, and 255. Differentiating these produces 0, 0, 155, 100, 0, 0, and 0. The change in intensity forms a pattern that highlights and describes the contour of the changes. If this object came closer to you the readings might be something like 0, 0, 85, 155, 210, 255, 255 and 255? The change pattern would then be 0, 85, 70, 55, 45, 0, and 0. Notice that the change over 2 sensors (85 plus 70) is the same as that over 1 sensor in the 1st example. Effectively we are trying to identify / recognize the shape of the curve (if it were graphed with intensity on the vertical axis) independent of the expansion of the horizontal axis (sensor position). One could also say, the 1st example is more in focus than the second is. An even more in focus sensor array would read 0, 0, 0, 255, 255, and 255. At this point the object has moved so far away that the edge occurs between two sensors. When closer we observe that the edge has a profile / contour pattern.
If it is really change in intensity per unit of distance then given intensities I1, I2 and I3 for widths of W1, W2 and W3 then the values at level 2 are (I1-I2) / [(W1 + W2) / 2] and (I2-I3) / [(W2 + W3) / 2]. If logs are used to replace division the values are Log (2) + Log (I1-I2) - Log (W1+ W2) and Log (2) + Log (I2-I3) - Log (W2+ W3).
16th April, 2013 E-mail to Mauri
Thanks for the reply Mauri,
I've scanned your blogs and it looks like you can certainly help me.
But first to answer your initial questions. From the recent work you have done this should all make sense to you.
What I am trying to do is develop a sequential pattern recognition software algorithm based on the deep learning that my binons perform (more below). One that learns. The software needs to be trained with an appropriate set of information.
As you know, for training software to recognize speech it is possible to obtain files which contain the audio information and the words that correspond. The word information is provided in synchronization with the audio such that given any N milliseconds of sound you know what vowel or consonant it corresponds to.
However speech contains many frequencies / pitches. I'm looking for the same sort of information but for only one frequency and Morse code would be a perfect example of this. The audio and the text could be in different files but the text file would also need to contain timing information as to where (time wise) in the audio file the character is heard.
The data file you used for training the SOM and PNN would be fine because it is the duration of the frequency bursts that matters. I have no interest in dealing with noise. But I do want human generated (not computer generated Morse) data because of its variability in durations. But even better would be a continuously labelled data file with the inter character and inter word durations as well.
The problem I am trying to solve is to add the time dimension to the learning being done by my deep learning binon (= binary-neuron) pattern classification algorithm that I call Perceptra. I have it recognizing 1D and 2D spatial patterns reasonably well. Now I want to do 1D spatial and time. Then I will expand it to 2D spatial and time which = speech recognition.
My website: www.adaptroninc.com describes my approach. (The notes section is not yet up to date.)
I have submitted a paper to the International Conference on Cognitive Modeling for July 2013 to be held here in Ottawa, Canada but have not heard back yet on its acceptance (or not). It is titled: Perceptra: A new approach to pattern classification using a growing network of binary neurons (binons). I can forward it to you if you are interested.
Is it possible for me to obtain the Morse timing data you have been using and is there available any continuous labelled stream that includes the inter character and inter word durations?
Thanks, Brett
PS You have done some awesome work with FLDIGI over the last year or two. I'm most impressed.
18th April 2013 Spatial frequency
So this contrast contour pattern is equivalent to the spatial frequency and may be a Fourier transform approach will work. That is deriving the frequency of the predominant sine wave that corresponds to the readings. I wonder if this can be done with just two or maybe 3 adjacent readings and their widths using some simple formula.
19th April 2013 Position
I could use the rectangular area that includes the combination of 1 or more of the smallest rectangles as the area of attention / focus. Then use the kinesthetic feedback from the eye muscles to produce a left / right and up/ down distances between these rectangular areas as the eye saccades over the image. This would not address the ability to pay attention to peripheral areas without moving one’s eyes. This peripheral attention mechanism is the only attention mechanism available in hearing.
22nd April 2013 Emotions
Anticipation is the idea of Pleasure and once pleasure is experienced we have Joy (aka Happiness).
Fear is the idea of Pain and once pain is experienced we have Sadness. Anxiety relates somehow to fear.
Anger is the feeling we have after we are unsuccessful at accomplishing a goal.
Satisfaction is the feeling we have after we are successful at accomplishing a goal.
Surprise and Boredom
Then there is; Trust, Disgust, Possessiveness, Depression, Lonely, Proud, Nervous, Giddy, Tired, Rage, Calm, Despair, Hope and more.
LinkedIn comment
First, my software/design is still being improved - it's research. So although it performs tasks it does not learn them as well as I would like. My perception learning is far more advanced.
Second, when learning to perform a task it will continue to evolve its solution until it finds one that satisfies its purpose. And that is a key point. We perform, and a robot should learn to perform tasks because of a reason (this is your "want to move"). It is all about purpose - the "Why" is it learning. I believe there are two important differences in motivational levels. The first is the motivation to pursue novelty (interesting, change and surprise, the opposite is to avoid boredom) and the second is any motivation tied to survival. Survival motivations are always associated with pleasant and unpleasant stimuli. Examples are food, rest, sex, healing (avoid injury) etc.
When a robot or my software comes up with a solution to a survival motivation / goal it usually stops and will stay with that solution provided it does not cause any other survival motivation to kick in. You will continue to search for food until you find and eat sufficient food or unless you become injured at which point this motivation will take over.
But the pursuit of interesting, novel, different experiences never ends because as soon as the same situation repeats you become bored. So this motivation will always keep it going searching / exploring its body and environment. Learning to walk is more a case of exploring the body than exploring the environment.
And another key point that I often make is that babies learn to do all sorts of things (including to walk), not because they experience pleasant or unpleasant (punishing or rewarding) stimuli while they are learning. They learn because of the novelty, the change that comes from the ability. This is reinforcement learning based on novelty.
On this subject you might want to read "Novelty detection for cumulative learning" at:
http://www.im-clever.eu/publications/publications/pdfs/conferencereference.2012-01-13.6465292201.pdf
The second part of what you are trying to do "how does it develop a task it has learnt to improve it [e.g. minimize energy usage] or adapt it for an unknown situation to quickly find a solution" is the REAL challenge. I like to point out that from a functional perspective there are two phases involved. The try phase and the practice phase. In the try phase we try to combine (sequentially or in parallel) two or more already learnt subtasks that may accomplish sub-goals that make up the desired goal. In the practice phase we repeat these two or more subtasks with slightly different / fine-tuned parameters (speed, force etc.) until we have optimized whatever the motivations are.
Then this task is learnt and can be done automatically and selected as a subtask in the try phase for purposes of accomplishing a higher level goal. How this is all done is still not clear. There are lots of ideas out there and lots of other functionally useful evidence from disciplines such as neuroscience, cognitive science, process control theory etc. that can be bought to bear on the problem.
23rd April 2013 Contrast Pattern
I want a contrast pattern that is recognizable independent of
- position - can move left and right
- size - can expand and contract - come closer and further away
- intensity level - overall intensity changes
It's a contrast profile - a texture profile - a contour pattern. If there is a sharp contrast we have a dramatic difference in intensity between adjacent sensors. A smaller difference in intensity gives a less dramatic sharp edge. A number of adjacent small differences in intensity provide a contour - a low spatial frequency. Sharp contrast is a high spatial frequency.
The difference between two adjacent intensities does not change as it changes position. The difference between two adjacent intensities does not change as it expands or contracts. What about the difference if both the intensity levels change in unison? When we go to the time dimension do the patterns of changes in intensity play a part in controlling devices? Or is it just the shape (duration that matters)?
24th April 2013 Intensity versus Gap/order
At any point in the control of a device we have the following stimuli et al.
- The current position / tension / intensity from a sensor,
- The expected / predicted / goal intensity for the sensor,
- A sequence of previous intensities from the sensor.
From these we can calculate:
- the difference between the current and goal intensities - the error
- the most recent change in intensity = the derivative of the intensity
- the derivative of the error = the negative of the derivative of the intensity
- The integral if the past intensities
- The integral of the past errors.
Is it possible that we actually use a PD controller rather than a PID controller for muscles? Then the finer tuning of our muscles is done by using other sensory feedback such as sight. This would only require the use of subtraction between intensities to calculate the relative intensity. This might be all that is necessary for control and especially where the sensor values do range over large orders of magnitude. But what about where the intensities range over such a large scale? Does a contrast pattern really make sense? Do we use or need a contrast pattern to identify / recognize things? Or is intensity contrast only used to find edges?
Gaps and order
Also maybe my binon network should not be ordered. Neurons don't know left from right. The left-of and right-of would then be represented by what would be equivalent to eye muscle movements. This might work for vision but does not make sense for hearing. But the idea does make the binon structure more general purpose and allows relative direction to be encoded as information and used appropriately as needed. On a 1D sense then the width pattern at level 2 would have to be replaced with a level 3 binon with 2 links to source binons. The 2 source binons would be to a level-1 relative position binon (left-of or Right-of) and the level 2 shape pattern binon that I currently use. This relative position binon could actually be my Gap binon with a positive or negative number.
My gap value must also be a ratio of the gap distance to the size of the 1st width so that it is always relative for object expansion and contraction. Given two widths at Pos1 and Pos2 with widths Siz1 and Siz2 and the gap is calculated as Pos2 - Pos1 then when they are adjacent the ratio is (Pos2 - Pos1) / Siz1. But when they are adjacent Siz1 = Pos2-Pos1 and so the ratio is 1. No zero values can exist for the Gap nor its ratio. This then allows the sign to represent the left-of or right-of information whether they are adjacent or not.
If I replace the contrast pattern with the Gap pattern with graduated readings this would be an order pattern equivalent to what is combined with the symbol pattern for discrete valued readings.
26th April 2013 Contrast patterns
I have noticed that contrast profiles are found within the borders of objects. They effectively convey the contour and texture pattern of the object by reflecting different light on the bumps and dips, ridges and valleys. Contrast at edges between objects is usually always sharp (also can have a colour change) unless the image is out of focus. When it is out of focus then the result is like contours with gradual changes in intensity. Sharp contrast changes between objects make sense considering that any two adjacent objects are physically different. But what about sound objects. The edges between different frequencies (volume = intensity) can be very gradual. Maybe this is where the spatial frequency comes in. High spatial frequencies (sharp edges) are preferred. But at some point low spatial frequencies don’t count (what do I mean by count?) as much. But these low spatial frequencies – blurred focus – contrast patterns are still visible. Or do they only show up when you move your eyes?
30th April 2013 Order of Source Binons
Binons should be blind to the order of the source binons. Given two source binons in either order they should combine to the same target binon. The target represents the combination of the two source binons. And since a binon is a class and it is symbolic then the experience needs to be represented by the target binon combined with an order binon. Implementation wise this can be achieved by giving each binon a unique number and always making the lower numbered source binon the first one. Then, no matter in which order they are presented they will always be found as the same target binon.
Shape Patterns
Given the adjacent shapes with widths 3, 1 and 4 the two patterns are 3/1 and 1/4. But 3/1 is the same as 1/3 but with a negative order. So using + and - to indicate order 314 is -1/3 and +1/4. 413 however would be -1/4 and +1/3. Given binon IDs the combinations would form as follows:
Object Binon ID Level Type Bin1 Bin2 Value
11 1 Order -1 -1 +
12 1 Order -1 -1 -
13 13 2 Shape -1 -1 1/3
14 14 2 Shape -1 -1 1/4
31 15 2 Shape 12 13 0
14 16 2 Shape 11 14 0
314 17 3 Shape 15 16 0
314 18 3 Shape 11 17 0
41 19 2 Shape 12 14 0
13 20 2 Shape 11 13 0
413 21 3 Shape 19 20 0
413 22 3 Shape 11 21 0
Do we need binons #18 and 22? Does a level 2 also need a contrast aggregated with it? Should we distinguish between dark/light and light/dark? I could use an intensity threshold to provide a binary contrast pattern rather than use the ratio of the actual intensities. Then a level 2 pattern becomes an aggregation of a width ratio, an order and a contrast order.
Adjacent shapes
And maybe I should also consider two level-2 or higher shapes as symbolic classes being adjacent to each other or separated just as I currently treat level-1 widths. And maybe they can only be treated this way after they have become familiar. This would slow down the formation of these shapes with or without gaps.
Patterns are classes
There are many instances that match a pattern and this means the pattern is a class of those things that match it.
4th May 2013 Gaps
I should only combine gaps with shapes when I have a time based process. The gap patterns are recognized because of "common fate", two or more parts move in unison. This requires time - change. Thus spatial only recognition should not combine pairs of shapes containing gaps from two separated familiar objects. The shape with the gap must exist first to be recognized.
However, combinations of two separate (non-adjacent) familiar shapes can be formed during spatial only recognition. As an example in the width list 4 1 3 7 9 5 the shape 4/1 and 9/5 may be familiar from a previous experience. These two could be combined to form a new combination without any reference to the gap. The only additional information would be 4/1 is on the left of 9/5. The result is a new class representing the coexistence of the two shapes. Only after a second frame (in time) occurs with the same shapes and relative gap separation would the gap version of this combination be formed as a single new class of shape.
But then how does the representation of 4/1 and 1/3 combined because they form the shape 4/1/3 differ from the same shapes found in the list 4 1 2 7 1 3. Maybe they should not be combined when they are separated unless they change in time. Maybe they should be seen as independent objects at the highest level of recognizable classes that occupy the frame. Only when they exhibit some consistent relationship over time can they be combined to form a new class. This would be true for the letters in a word. They only form the combination because they have been seen two or more times in the given order.
Repeats in the same frame
If a shape exists for the first time, two or more times in a frame / experience, I should be marking it as familiar (not novel as I currently do). Then it should also be counted as a result, independent of the occurrences being adjacent or not.
Contrast order
I like the idea of using a contrast threshold or even better a contrast order. A contrast order would be a property of a two-width shape. It would indicate whether the left width was darker or lighter than the right width. It would only be local between the two widths. What would happen for a three-width shape? Would I form a pattern of the darker/lighter relationships?
5th May 2013 Contrast / Edges
I've decided to try using the 2nd derivative of the intensity equal to zero as the edge locations. This is basically where the change in intensity goes from being positive to negative. On a blurry edge from dark to light the intensity starts getting lighter and this is a positive change, accelerating. Then at some point it slows down and gets lighter more gradually as it reaches the full brightness level, decelerating. It is at this point between acceleration and deceleration that the edge is located.
14th May 2013 The border
Although the border should play no part in the recognition of the shape, my current algorithms get a much higher prediction rate if rectangles include the border as one of their edges. The bordered rectangle is combined with one from the digit's shape and this combination is more distinctive. What I think is really happening is the shape of the digit's edge is being represented. I think what I should be trying to represent is the curvature of the edge and whether it accelerates or decelerates.
Perceptra 2D test runs 14th May 2013
17th May 2013 Edges
I've been thinking about how to detect and represent edges. I've been thinking about all the combinations of edges that are possible and the most natural way to represent them. The edges being considered are either vertical or horizontal and are straight lines with a particular length. The combinations include two edges meeting at a corner (4 possible), two edges meeting where one comes into the middle of the other forming a T-junction (4 possible), and four edges that meet at a point forming a plus sign. These edges would then get combined at greater levels of complexity to form patterns based on ratios of their lengths. The only problem occurs with the T-junction. Considering the orientation of a T, the top edge is a single edge for the shape above it and is a combination of two horizontal edges, each for a shape on the sides of the vertical edge.
Sides
The solution is to use sides of edges as the most primitive component. Then the T-junction is the aggregation of 5 sides. The side on the top goes all the way along the top edge. The shapes on the left and right of the vertical edge each consist of two edges. The left shape consists of the underside of the left part of the top edge and the left side of the vertical edge. The right shape consists of the underside of the right part of the top edge and the right side of the vertical edge. Each side will also have an intensity reading and these must be the same for any two sides to be combined to define the shape.
To represent a side, the following information is possible. The start x and y co-ordinates, the end x and y co-ordinates, the length, whether the side is vertical or horizontal and the intensity reading. The length can be derived from the start and end co-ordinates, as can the vertical / horizontal property. Therefore the 4 co-ordinates and intensity are going to be used to represent a side.
23rd May 2013 Order of Binons
Continuing from the 30th April 2013. Given any number of independent source binons / classes there should be a unique P-Habit binon that represents the combination. Then any configuration information should be in a separate binon. How to generate this P-Habit binon needs an algorithm that can work with the fact that any two source binons can occur in either order but only get represented in one order.
26th May, 2013 LinkedIn Discussion
Any habit that requires action such as speech that has been practiced and learnt to the point of being automatic and can be done close to subconsciously is being done by your cerebellum and not your cerebral cortex. The process of switching between the two languages requires working memory in your cerebral cortex and needs conscious attention. However just like learning to say the alphabet backwards you can learn to count alternately between two languages and make it into an automatic habit. It just takes practice.
30th June 2013
See the 2013 Scientific Research and Experimental Development (SR&ED) tax credit claim.
Details about the Canadian Revenue Agency’s SR&ED tax incentive program are here.
1st July, 2013 LinkedIn Discussion
The fact that the principles of operation for intelligent behaviour (learning and thinking) have not been clearly enough defined, for the purpose of modeling and reproducing it, is definitely a major contributing factor to the slow progress of AI. I am taking a bottom up approach to developing AI. This approach starts by modeling AI at the simplest possible level of complexity. One sense, one sensor, one device, one action and adds complexity once it works at the previous level. But as my website mentions this approach is challenged due to a lack of clear, unambiguous test cases for intelligent behaviour.
10th July 2013 Simplest prediction
I've been thinking about and trying out different strategies for using the associated name binons for predicting the class of an experience. I believe that the lowest level of complexity unambiguous class binon should be used. These are the first ones to uniquely identify a name binon in the bottom-up process of finding property binons. This seems appropriate because it is the fastest approach. But once the unique name binon has been found at this lowest level should the higher levels be searched / created? Are higher level combinations useful? Not if the first unambiguous ones found are used for prediction. When I try this in Perceptra 1D prediction success rates are down in the 60% range. If I use the first name binon that is predicted twice, it does a better job.
19th July 2013 Ambiguous labels
In the current Perceptra binon network structure the associations that class binons have with name binons are kept even though the class binons become ambiguous. A new idea is to remove these associations as soon as two class binons that are associated to the same name binon are found co-incidentally and are combined to form a target binon. The two source binons must be ambiguous. Does this free up the source binons to be more accurately labelled? It's like saying straight lines are combined to form all categories of letters but a straight line is not a letter. It is part of a letter. But a straight line still should be associated with the name binon for "Straight Line".
Dependent to Independent
Another approach to recognizing patterns in dependent sensors is to treat them all as independent sensors (give each sensor a number, create all possible pairs and then create higher levels with overlapping parts - equivalent to all binary numbers). Then only the coincidental combinations of familiar source binons will be formed so the hierarchy will grow slowly and only for reusable patterns.
25th July 2013 Where versus What
Back in October 2010 I spent some time thinking about the where and what properties of a stimulus and the fact that paying attention is the processes of given the where part of a stimulus, retrieving the what part or vice versa. Today I realized the where / what parts are the same as the property type and its value. And it is the same as an address and its content. Now the challenge is (as it was on 14th June 2010) to use the binon structure to correctly represent the combination at all complexity levels for both graduated and symbolic stimuli.
For the independent senses the where information must contain the unique (nominal) representation for the sense (most likely an integer). For independent sensors within a sense the where-information must also contain the unique sensor number. Then a complex stimulus's where part would be a pattern of sensor numbers and sense numbers. For dependent sensors in a linear array the where information must be position independent and thus must be relative position information. Since adjacent readings or widths are used to produce ratio patterns that are symbolic the relative position information must be either "on the left of (L)" or "on the right of (R)".
If we then experience 6/1/6 we want to have a "what" representation for the two ratios 6/1 and 1/6. But is the 6/1/6 pattern represented as L^(6/1) ^ R^(1/6) or L^R ^ (6/1)^(1/6)? The first representation buries the where information at all levels of complexity. The second representation separates the where information for easier retrieval. At the next level up representing 6/1/6/7 the two possibilities are:
[L^(6/1) ^ R^(1/6) ] ^ [ L^(1/6) ^ R^(6/7) ] or [ L^R ^ L^R ] ^ [ (6/1)^(1/6) ^ (1/6)^(6/7) ]
Maybe this works for edges and the contrasts produced at the edges. But maybe the widths are really the where properties. One edge is on the left of a second edge by a certain distance. The left-of and right-of information is captured in the order of the source binons. It then takes two edges to produce a width and three edges to produce a width ratio. These width ratios are shapes and they capture where the parts (the whats) are relative to each other. And it takes a shape (where) and a contrast (what) combined to uniquely identify something. This is because each shape can have many contrast patterns and vice versa. Just as a location could have many contents and vice versa and a property can have many values and vice versa.
So even though an edge is a pattern and it is represented symbolically it is just a piece of what information - a value. It can be re-recognized and searched for. When found it will be at a particular location / position. Then two edges provide a width because of their relative position. But this width thing is not yet a where property because it is not yet a re-recognizable pattern. However the combination of two edges with no intermediate edges does produce an area of a single intensity. No - I don't think the widths and shape patterns are the where properties that are used for paying attention. Shape patterns and contrast patterns are all what information and just happen to be complicated because one can have a shape pattern composed of shape patterns as a result of how positions and widths work.
So for dependent sensors the where-information is not the relative position of parts to other parts. It is the relative position of a part to a fixed point in the field of vision / observation. And for paying attention the search can be based on a one or a pair of relative field position, a shape pattern and a contrast pattern but not all three. The one or two parts not included in the search criteria are returned. For example you could search based on just a shape and the field position and contrast pattern are found. You could search based on a contrast pattern and the field position and shape are found. You ask for a shape and contrast pattern and its field position is returned if it exists in the field of observation.
Now let’s get back to the question of combining the "where" with the "what". For dependent sensors the where should be the relative distance to the edge of the field that the part is from the centre of the field of observation. Math wise this would be the ratio = the distance from the centre to the part divided by the distance from the centre to the edge of the field of observation. If the IDL is used to represent this ratio then it will be more accurate at the centre and less so towards the edge. This would then imply that every part (shape and contrast pattern) should be associated with a sense and relative field position combination.
But also the size of the area to be focused on is necessary so that a small area can be identified in which a lower complexity part is found. Then this part, which may have become ambiguous, can be associated with a name class. This allows for the learning of a straight line even though up to this point only digits or letters have been learnt.
Ambiguous labels
This idea would apply to any source property binon that is shared by two or more target binons that are of the same property but not necessarily of the same property as the source binon. The source binon would be marked as permanent. It could continue to be shared.
Edges and Sides
I don't think I should be using edges as the level 1 contrast binons. I think the sensory system uses the edges, because that is where the change takes place, to position the sides that provide for a width. A width consists of two sides. Then two widths that are beside each other provide for the level 1 shape binon and the ratio of the intensity of these widths provides the level 1 contrast binon. Then level 1 shape binons have a width and a position. These can then also be used in combinations so the same shape can be recognized at higher levels of complexity. But their contrast binons are not combined.
26th July 2013 Compositional hierarchy
When we perceive an object we pay attention over a short period of time to many different areas within the observation field. We then build up an S-Habit representation of this object from a composition of all these parts. These parts are the ones that allow us to identify the same object when part of it is obscured. So the S-habit is a series of perceptions of the object's parts. The parts are the ones that changed in unison from one frame to the next within the area of focus. Can the same effect be obtained for supervised learning in which the named classes are presented at random? They are not related by being adjacent in time but they are related by being labelled the same. If the name binon maintains the most recent associative binon between the name binon and class binon then the most recent class binon could be treated as the previous in time perception. Then those parts that have changed in unison could be extracted as truly belonging to the named class.
Repetition
By running the Morse code recognition program I have come across a situation when I need to recognize repeating patterns and not be interrupted because of boredom. The letter S is 3 dits in a row and the letter H is 4 dits. Obviously the sense is being concentrated on and attention is directed. The STM routine should not stop combining the repeating pattern. Only when attention is attracted or directed away from this sense should the STM be flushed. May be STMs that are assigned to each sense and that work subconsciously might not retain a repeating pattern.
Quantity
I'm faced with a problem if I continue to combine quantity of repeats with a stimulus in a single sense because the combination is not what repeats. It is the stimulus without the quantity that repeats. The solution appears to be; make the sense of quantity into exactly that, a different sense. Then the stimulus can repeat within its sense and the quantity only gets added when combining senses. Thus STM works within the sense and quantity is combined afterwards. Or maybe it is better to think of the STM process generating the quantity stimulus. I am referring here to a sequential quantity rather than a spatial repetition / quantity.
27th July 2013 STM
I’ve been trying out adding quantity to repeated stimuli in STM and then labeling the results for recognizing Morse code. One challenge is to do with the fact that the character label is only provided at the end of the dit / dah sequence. I have a feeling that one of the things I should be doing is emptying STM when the label is given because attention is attracted to the label. Or should the label be part of the sequence? Also should a repeat be the class binon plus a quantity or should a pair of class binons that repeat be combined into a new/different class binon. Is the repetition a pattern?
Combinations
I have improved Perceptra 1D in supervised mode by changing the criteria for combining two source binons. They must both be non-uniquely labeled to be combined. This generates fewer binons but reaches about the same prediction rate. It also allows familiar unlabelled binons to be combined with ambiguous ones.
28th July 2013 Quantity / Repetition
The quantity should definitely be another property that is combined with the repeating binon. This is because we can pay attention to the quantity independent of the thing that repeats.
Pruning / Forgetting
If an association-A1 between a class binon-C1 and name binon-N1 becomes unused because the class binon-C1 as a source binon gets combined with another source class binon-C2 to form a target class binon-C3 that then gets associated-A2 with the same name binon-N1 then the association-A1 can be pruned. This is because the class binon-C3 gets found before the associations are used to navigate to the name binon. Association-A2 will always be used rather than A1 and A1 can be pruned. This will mean any other associations that C1 has with other name binons will remain as valid. If this reduces to just one association then there is a unique name for this "sub-category" as in "straight-line". This solution is a more refined approach than the 19th July 2013 in which both source class binons were associated with the same name binon. This pruning of unused association binons is also neurologically plausible. As my wife just said "use them or lose them."
30th July 2013 Ambiguous / Unique
I have realized that the criteria that a class binon be unique or ambiguous should be used in paying attention but not in the perception of the stimulus. In perception the co-incidence and familiarity are the criteria for forming new property binons. And the process of predicting the class name of a property binon is the process of paying attention to the class name property when given the shape property (for example).
4th August 2013 Edges and Sides
I've been trying out my idea from the 25th July and naturally get an explosion of level-1 widths and masses of level-2 shape ratios. This is certainly the way to create all possible shapes that will include ones with gaps. But I think motion is required to make these extra level-1 widths (from using a level-2 shape as a width) familiar and then reusable. Or will combining repeating patterns do it for me. Maybe a level-2 shape that is repeated anywhere in the image becomes familiar and only then does it become a level-1 width for combination.
5th Aug 2013 Pruning / Forgetting
I have the pruning version working as well as the one that just accumulates lots of ambiguous binons. I also have it creating linked lists of associating binons that combine the class binon with the name binon. Now I have the question about should the name binon be associated with each of the property binons that comprise the class binon? I believe it should be so that we can name a square and have it associated with just the shape property but name an apple and have it associated only with the valid shape and colour combinations. Thus a purple apple is not an apple. The idea would be to prune the association between the name binon and any class properties that were not being used. Similarly a quantity property can be named independently of the items. And if the name binon gets associated with each of the property binons and all of their class binon combinations, how does the pruning rule work such that the property or properties that are irrelevant get their association to the name binon deleted?
Order of combinations
The last combinations of binons are made across different senses. But within a sense are the binons within a property combined before or after combining binons across properties? Combining property binons across properties produces class binons. Combining property binons within a property produces more specific categories of that property. We can pay attention to these more specific categories of a property while disregarding another property. For example: paying attention to shape but not colour or contrast. But we can also pay attention to a class binon that combines two or more properties at any level. For example: paying attention to the quantity of the blue squares but not the red ones. Or do both combinations get produced and the unused ones get pruned?
6th Aug 2013 Dependent to Independent
On the 19th July 2013 I experimented with treating things that were dependent (because they are beside each other) as independent. My note talks about doing this at the sensor level but the experiment did it with the level-1 property binons (ratios of two widths). It worked but created a lot more high-level combinations. The idea is that any dependency, whether it is a result of the sensors being beside each other or not, will be discovered in the process and therefore need not be assumed and built in to the way the sensor data is processed. When it's built in, the process is more efficient because it takes advantage of the dependency in determining the level 1 shape binons. Treating them all as independent basically recognizes configurations of sensor values. As such they are position (sensor) dependent. But I want position independent patterns.
Order of combinations
Upon detailed analysis of the possibilities it looks like I need to 1st combine the lowest level property binons for the smallest part (2 widths beside each other (adjacent)). For example this would combine the level-1 shape ratio with the level-1 contrast ratio and level-1 temperature ratio into a level-3 class binon for the two widths. I have purposely chosen temperature rather than colour names as the third property because temperature values are graduated and colour names are symbolic. Then this would be done again for the next smallest part (pair of widths) in which the 2nd width of the first part is the 1st width of the second part. I.E: overlapping widths. It is then these overlapping class binons that should be combined at higher levels of compositional hierarchy to form binons that more accurately represent the specific object instances made up of these parts. In parallel the compositional hierarchy of each property binon or pair of property binons can be formed to create more complex categories of the property. For example more complex yet specific shape patterns. In 2 dimensions, such a shape hierarchy may be points, straight lines, rectangles and windows. Both approaches are needed because of the ability to pay attention to the category independent of the instance or to the instance.
7th Aug 2013 Order of Combinations
I have been building the hierarchy of class binons from the level 1 class binons (which are a combination of the level-1 property binons) and using these to recognize the hand-written digits and the accuracy result is the same as recognizing shapes.
Where versus What
I also dealt with this issue on the 4th Sept 2009 under the title Order Information, although here I was dealing with the sensor order for independent sensors. But it brings me back to trying to symbolically represent a width from a linear array of dependent sensors as a part. I feel the need to do this so that a width of the same value can be re-recognized when it repeats somewhere else in the array. This is like recognizing random dots on a page as all the same type of thing. The solution appears to be based on the approach I documented on the 25th July 2013. This approach says that the first thing to do is to find the changes / edges. Each edge has two sides. With two edges one can determine the distance / width (quantity of sensors) between them (the sides that are facing each other). One can also determine the intensity of the sensor readings between the two edges. This combination of width and intensity could then be the smallest re-recognizable object. However what if it is closer to the sensors and therefore has a greater width? Isn't it still the same object? Yes, if it has moved and time has passed. But what if it is in the same frame, the same size but separated spatially. Now we start to recognize a quantity of them. But in one dimension the background sections are widths as well, just a different intensity. This is relevant for Morse code. What is it that says the information content is in the dits and dahs rather than the gaps between them? If the gap length held the information then it would just be the negative of the normal signal. And in fact the length of the gaps do hold information, they indicate end of letters and end of words.
8th Aug 2013 Edges, Sides, Widths and Quantity
I've had further thoughts about this issue that I have had before. (19th June 2008, 14 Aug. 2009, and 17th May 2013). Width is really quantity of sensors. Each sensor measures intensity and has a position. An edge occurs between two sensors that are next to each other, based on their order of dependency (adjacent), that have a difference in intensity that is just noticeable according to the Weber-Fechner law. An edge is composed of two sides. Each side is a sensor and therefore has a position and intensity. An edge has quantity (think width) of zero. Because it contains two intensities its value is the ratio of the two sides (a contrast). A width is composed of two sides, has a quantity (width) equal to the number of sensors between the two sides and an intensity which should be the same for the two sides within the just noticeable difference.
9th Aug 2013 Quantity
Based on the approach from yesterday, if I was to treat each sensor as a target binon that provides a position and intensity I just might be able to develop a uniform algorithm from sensors all the way up the binon hierarchy. The process alternates between two steps. The first is to combine adjacent source binons that are the same (repeat) and reproduce it with a quantity and intensity. The second is to use overlapping source binons to identify higher level patterns / categories. The first step I have experimented with and programmed already. It results in the removal of all the binons that are found in the scope of repeating binon. These repeats can be shape repeaters, contrast repeaters or class binons repeaters. The second step combines overlapping source binons at one level to create identifying target binons at the next level up. These are shape, contrast and class binons. Class binons are combinations of class binons. Lowest level class binons are the combination of the lowest level shape and contrast binons. At each level there will be a shape binon, a contrast binon and a class binon triplet that represents a given number of widths at the sensor level. Each of these three binons will also have a quantity that will be used in the production of the ratio that will be stored in the target binon when they are combined in the second step.
17th August 2013 Combining Repeaters
I'm in the process of getting the code working that combines repeated shape or contrast patterns. I have been using an algorithm that uses the position and size of the patterns as kept in the activation tree to determine adjacency (next to each other). However, I have a better idea. At level N adjacent patterns are found every N+1th entry in the list. At level-1 every second binon is adjacent. At level-2 every third binon is adjacent. No need to use position and size. This is still true even if a repeating pattern is combined and given a repeating quantity. However when repeaters are replaced with one instance of the binon and this is combined at higher levels the repeaters at these higher levels are only valid provided we check all the to-be-removed binons between the repeaters are the same as the next ones after the 2nd repeater.
Perceptra 1D test run 17th Aug. 2013
16th Sept 2013 Permanent
When a property binon becomes ambiguous and all its associations with class binons are pruned maybe then it becomes permanent and can no longer be classified.
Attention
When processing the Morse code I need to consider three senses. One is time. The sense of time should produce a clock value that can or maybe is associated with the other stimuli. Differences in clock values of two stimuli produce the duration between them. The second is volume. The sense of hearing produces this at just one frequency. Frequency therefore is not a property. The third is symbols, which could be from the sense of sight. This symbol sense produces a blank if attended to during the dits and dahs of a letter and the actual letter at the end of a valid letter sequence. Thus, when the S-Habit is being practiced and attention is paid to the expected letter the observed letter may be a blank or a letter.
Change
I have already mentioned that the information is in the difference / change and without a difference or change there is nothing of interest. However if the difference or change is below the level of significance according to the Weber-Fechner law we do not notice it. But it should be a difference per unit of distance or a change per unit of time. For two sensors beside each other (adjacent) it defaults to the difference between the two sensors (a unit of distance of one). But what about for two sensors that are further apart? Can a change be so gradual that from a sensor at one end to the sensor at the other end there is a significant / noticeable difference but there is no noticeable difference in the in-between sensors? Obviously if this was the sense of sight we would move our eyes from one end to the other of the image and obtain the difference as a change over time. This is how we can observe such differences by shifting our attention. And the only way we can detect a gradual change over time in a sensor reading is to have some memory of the earlier reading and compare it with the current observed one. But even then the memory must be relative to another memory of a reading and the observed one is not the same relative to the other.
Combining Repeaters
The idea from 17th Aug 2013 does not work because the Level N does not contain all the binons that could be generated. Only the ones with familiar source binons are in the activation tree and these are not always adjacent to each other.
17th September 2013 Association Binons
The association binons are the ones that connect a class binon with a name binon. The class binon represents a spatial / parallel / simultaneous combination of stimuli from one or more sensors and their properties. The name binon originates from a different sense and is presented after the experience that it labels. This means the association binon is an S-Habit - sequential / over time association. (I changed this to an A-Habit on the 18th Sept.) They are the ones that get pruned. Therefore any learning here involves attention and switching it from the experience to the name and also involves an expectation, which is the prediction step in Perceptra 1D.
The association binon is also an "is a" relationship, not a "consists of” relationship.
Quantity
I'm still not sure I'm dealing with quantity correctly. In the latest version of Perceptra 1D I combine repeating patterns and in the activation tree I place the binon that repeats plus a value which is the quantity of times it repeats. When it is combined as a source binon with the binon adjacent to or overlapping with it the resulting target binon is given a value of the ratio of the quantities. This means that quantity is relative and the JND applies. But back on 28th July I said quantity is a property that can be attended to just like colour and intensity. Thus it would seem a separate property binon should be used.
18th September 2013 Levels of Complexity
To solve the ability to recognize patterns independent of the level of complexity I need to make level-0 widths out of higher level objects. These widths must then be combined and found in the known binons. They must not be used to create new binons. So it is a process that takes place after the creation of the activation tree that combines adjacent familiar source binons into novel target binons. This level of complexity recognition uses a very similar process to the creation of the activation tree but only finds higher level patterns, does not create them. An example is:
These binons are already known:
# Level Source 1 & 2 Pattern
1 0 -1 -1 1/1
2 1 1 1 2/1
3 1 1 1 1/1
4 2 2 3 2/1/1
5 2 3 2 2/2/1
6 3 4 5 4/2/2/1
The input pattern has property values of
Position: 1 2 3 4 5 6 7 8 9
Values: 9 9 9 9 1 1 9 9 1
Resulting in widths of 4, 2, 2, 1
The activation tree is then:
# level Source 1 & 2 Quant Binon Position. Size
1 0 -1 -1 4 1 1 4
2 0 -1 -1 2 1 5 2
3 0 -1 -1 2 1 7 2
4 0 -1 -1 1 1 9 1
5 1 1 2 1 2 1 6
6 1 2 3 1 3 5 4
7 1 3 4 1 2 7 3
8 0 5 5 6 1 1 6 These 3 are #s 5, 6, and 7 made into
9 0 6 6 4 1 5 4 level-0 widths
10 0 7 7 3 1 7 3
11 1 1 9 1 3 1 8 These 2 are 1/1 and 2/1 patterns
12 1 8 10 1 2 1 9 found using level-1s as widths
13 2 5 6 1 4 1 8
14 2 6 7 1 5 5 5
15 0 13 13 8 1 1 8 These 2 are #s 13 and 14 made into
16 0 14 14 5 1 5 5 level-0 widths, no patterns found
17 3 13 14 1 6 1 9
18 0 17 17 9 1 1 9 This is # 17 made into a level-0
This approach should find all patterns at all levels of complexity including ones with gaps provided they have been previously created due to coincidence. Combinations of the found binons, such as those at 11 and 12 would also be found if they existed in this recognition process. Found binons would not be combined with created ones at the same level. The created ones have been copied into level-0 widths and are covered by the found ones.
Attention
When we pay attention we are focusing on an entry in the activation tree. This is how we can pay attention to a particular width or edge even though they are level-0 objects. We don't remember them however because we cannot re-identify them. This idea ties in with the 25th July 2013 thoughts about “where and what” and the field of focus / attention.
Generalization / Discrimination
Learning involves associating names or other important roles to stimuli (such as using the stimulus as a trigger or result). Like when you see a cow for the first time and are told it is a cow. At this point the label cow is associated with all the parts that make up a cow and if you see any one of these parts in another scene you expect / predict the cow label. This is generalization. The fear of all snakes is another example. If you see a cow for the second time you now form more specific combinations of parts such as a head, an udder or a tail. If you are told this is a cow then these more specific aggregate parts are associated with cow. If you then see just part of a cow, its head, you expect / predict the cow label. If you see these parts but not in the shape of a cow head but a dog head instead (the dog head aggregation is novel and has no associated label), then you are not sure if it is a cow but have no other label to use. If you are told it is a dog then the parts are associated with dog and become ambiguous. The dog head gets associated with the dog label. You can now distinguish between a cow and dog based on its head shape. This is discrimination. You have learnt to discriminate between cow and dog even though they share the same parts. The feedback / association formed from the role that the stimulus played in the scenario was used to provide the discrimination. If instead you were told that the thing you saw was an animal then all the parts and their aggregations would have been labelled as an animal. The more specific aggregations would all be associated with the animal label and the generalization would be maintained. This scenario is the labelling game. Given a stimulus find its associated label. In reverse it is given a specific label, draws a stimulus example. These two "games" / scenarios are A-Habits. Whereas an S-Habit is the sequence formed when there is no change in attention. Hearing a sound that takes some time or watching an object rotate forms an S-Habit.
19th September 2013 Attention
We have to be paying attention to a sense in order to learn anything new from that sense. This includes perception as well as action sequences. But what is the sense doing when you are not paying attention to it. It is sub-consciously recognizing anything that has been previously learnt on that sense. It is matching input stimuli with known patterns. This is why you can recover a short piece of what has just been said when you switch your attention from thinking to hearing. But if the language spoken was foreign to you the recovered item would be much shorter. The same is happening in vision. Recognizable/known complete objects are being recognized automatically and are ready for immediate observation when you switch your attention to your sight. This means that each sense needs a STM that is recognizing S-Habits but not creating novel ones. This STM should only hold the last recognized S-Habit. Should it be per sense, per sensor or per property?
Morse code test run 20th Sept. 2013
3rd October 2013 Quantity
In my new STM algorithm that creates S-Habits I have been counting repetitions of patterns when they occur. The stimulus that I have used has been the time / duration property. But I have some special code that counts repetitions at level 1 when two sequential adjacent binons are the same. For example, if the durations are 82, 82, 82, 82 milliseconds and the 1 to 1 duration ratio is binon #5 then this will result in the sequence of 3 binon #5s. The other repetition quantities are found every (N+1)st binon at level N. (see 17th Aug 2013). For example, if the durations are 132, 33, 132, 33, 132, 33 milliseconds and the 4 to 1 duration ratio is binon #7 and the 1 to 4 duration ration is binon #9 then this will result in the sequence of binons #7, #9, #7, #9, #7. The #7 binon repeats every second binon and represent 3 repeats of the 132, 33 pattern. But we only should form memories when there is information worth remembering and this occurs when there is a change or a difference. This is the habituation of a sensory neuron. Thus it seems to me that the level 1 adjacent same / repeating binons should not be counted. The change in a different sense, other than that of time / duration, that caused the 82 millisecond duration is what is really important. Thus if a change occurs on one sense there is a pattern of the stimuli from that sense plus there is a duration pattern from the sense of time.
When processing Morse code the change occurs on the sense of hearing between the dit and dah or vice versa. At these instances, duration is also available. If the duration between a sequence of dits and dahs is 82, 82, 82, 82 then the binons that are created are dit&82 and dah&82. However on the sense of time there is no quantity kept for the 82-millisecond duration because there is no pattern detectable. Now, if in parallel with hearing the dits and dahs, one also sees the valid letter flash at the end of the dit and dah sequences for each letter, then one sees no letter (a blank) at the intermediate dits and dahs. At these intermediate events the stimulus on the sense of sight is not changing, just like a sequence of 82-millisecond durations. Thus the repeating stimulus for no letter should not be counted at level 1. But how should the following sequence be represented? The “-" represents no letter (a blank) and $ represents the letter.
Sense Sequence of stimuli
Event # 1 2 3 4
Sound dit dah dit dah
Sight - - - $
Time binon 82 82 82 82
Duration ? 1/1 1/1 1/1
STM S-Habit sequences for sound are formed representing dit/dah and dah/dit and at event 4 the dit/dah would be given a quantity of 2 because it repeats. The STM S-Habit for sight would only be created at event 4 and represent -/$. No STM S-Habit duration pattern would be formed since the level 1 1/1 ratio repeats.
Based on the principles of the 6th Aug. 2013 I should combine binons across properties only at level 1. Then I should form hierarchies of each property and of the level-1 combinations. I should not combine level 2 or higher property binons because these are less specific. If I treat each sense as a different property in the above dit dah sequence example I should be forming 4 additional combinations for each event as follows.
Event # 1 2 3 4
Sound & Sight dit & - dah & - dit & - dah & $
Sight & Duration - & ? - & 1/1 - & 1/1 $ & 1/1
Sound & Duration dit & ? dah & 1/1 dit & 1/1 dah & 1/1
Sound & Sight & Duration dit & - & ? dah & - & 1/1 dit & - & 1/1 dah & $ & 1/1
Based on level 1s repeating adjacent to each other the Sight & Duration S-Habit pattern should not be formed until event 4. It should then be (- & 1/1) / ($ & 1/1). These combinations will be formed and their S-Habit sequences provided attention is being paid to these senses. And attention is attracted to a sense when there is a change. But are only the changed sense values combined at this time or are all the values on the senses combined even though some didn't change. If it is the former then only the dit/dah S-Habits would be formed during events 1 through 3 because the sense of sound is the only one that changed. If it is the later then all the 3 property binons and 4 possible combinations are formed at each event as shown in the example.
Should the same sequence occur later, then it would be important to recognize it. This would imply that the 1/1 should be part of the remembered sequence even though the duration has not changed. This would then allow for the recognition of the same sequence with a 132-millisecond duration of each sound. But what about the expectation of the $ at event 4 after event 3 has been experienced? We are expecting the complete dah & $ & 1/1 combination. If the "-" (no letter) is experienced instead, then this attracts attention. It is as though when the sequence is first experienced we have the combination of senses that change attract attention and this is something that is done as part of the action habit but the combination of stimuli remembered contains all the senses' and sensors' stimuli. This means the senses that make up the combination of stimuli that are remembered should not be used to control the attention when the sequence is being repeated and we are conscious of it. Thus the action habit should have as part of the acton a list of the senses and sensors to focus on after the action part has been performed. In the case of the name-the-class-of-object game this would be an action habit with no device activity. Each acton consists of a trigger stimulus and two pointers to the two slave-actons. The trigger stimulus is what attention is paid to and this need only be the subset of the senses and sensors that attention was attracted to when the action habit was learnt. However the sequence of stimuli experienced / remembered needs to contain all the senses and sensors so that should anyone of them not match the experience the difference attracts attention.
In summary when attention is attracted to a change or an unexpected stimulus the entire situation is remembered but only the changed senses and sensors are incorporated into any action habits that are learnt. This allows for the action habits to be performed subconsciously (by the cerebellum) based on the recognition of trigger stimuli that have a reduced level of complexity than those that are recognized and remembered (by the cortex).
4th October 2013 Attention
A variation from the 19th Sept 2013 is that the senses are forming the S-Habits subconsciously (in the cortex) from familiar stimuli but do form novel combinations if they experience them. Then ones attention is attracted to the novel / unexpected interesting stimulus. One does not need to be paying attention to the sense before the novel stimulus can be formed. When ones attention is attracted to the novel stimulus a new acton is formed that gets executed the next time its trigger stimulus occurs. Then one is expecting the novel stimulus. If it re-occurs then it will be familiar and the acton will be available for incorporation into other action habits.
But while concentrating on performing a task the novel combinations from the unattended sense or sensors sometimes do not attract attention. The novel combinations that do not attract attention do not get remembered. There is obviously a concentration level involved. There is the level in which we are performing the task to obtain a result that we think is rewarding. A novel stimulus would not interrupt this task. There is the level in which we are performing the task to obtain a result we think is interesting. A novel stimulus would interrupt this task.
Repetition of any familiar sequence that is done subconsciously does not attract attention and no count of the repeats is kept. This is because the familiar sequence is habituated. However if attention is being paid to the sense then the repetitions are counted so that one can recognize the difference between the Morse code for an I, S and H that are 2, 3 and 4 dits respectively.
5th October 2013 Action Habits
The last time I seriously worked on action habits was early July 2012 up to 22nd July 2012. Now I must further elaborate my ideas in this area to recognize Morse code. One idea I have is that S-habits that consist of sequences of stimuli that change from one sense / sensors to another are actually action habits with "do nothing" acts in them, orienting action habits. But they do have goal stimuli and these are the expected stimuli after the trigger has been experienced. Action habits are formed from the series of novel stimuli that occur and these can jump between senses, whereas the subconscious S-Habits are formed as described on 3rd Oct, 2013.
The main loop in Adaptron to process action habits needs to be clearer.
1. Get stimuli from all senses / sensors and form all combinations that match familiar stimuli.
- This happens when a change occurs on any sense / sensor. This includes all areas of sensors that attention is not focused on. It also includes finding all familiar sequences / S-habits of stimuli on senses and combinations of senses. Novel stimuli get created but do not get remembered unless attention is paid to them?
2. Perform all subconsciously executing action habits that are expecting stimuli.
- This does not mean perform their acts but just indicate that their expected stimuli have been perceived. Any that do not get their expected stimuli stop. The others continue.
3. If practicing an action habit attention will be focused on an expected stimulus.
- 3.1 If we get the complete goal stimulus the action habit becomes learnt, not interested in being redone. It will also be combined with the subconscious non-looping ones that were being done in parallel.
- 3.2 It will only be distracted by a stimulus within the attention focus area that is different from the expected one. A pleasant or unpleasant stimulus will distract the attention from completing an action habit that is being practiced with a redo interest based on achieving a novel goal but not a pleasant goal.
4. Else if not practicing the most interesting stimulus attracts attention.
This is the biggest combination / longest sequence that is novel.
- 4.1 If there are no interesting stimuli then a familiar stimulus attracts attention. This is the biggest combination / longest sequence that is caused by a change that is familiar. These stimuli are the ones created in the STMs and do not include sequences that switch between focus areas of attention such as switches between senses.
5. Find any action habits whose trigger stimulus is the one to which attention is focused.
- 5.1 If pleasant and unpleasant goal stimuli exist then the most recent action habit with a pleasant goal will be started and provided it is learnt will be done subconsciously.
- 5.2 If there are action-habits that have redo interest then start the most recent one.
- 5.3 Else if there is no action habit with a redo interest then pay attention to the goal stimulus and repeat at step 5.
- This is thinking of the goal by traversing the action habits for this stimulus as the trigger. This repeats until we come across an action habit that has a redo interest or an expected pleasant goal stimulus is encountered.
6. If an action habit is selected then perform the action of the selected action habit
7. Else if no action habits exist for the attended to stimulus, no action habit is being practiced.
8. Perform the actions on all continuing subconscious action habits.
9. Set up the attention to expect the conscious stimulus and the subconsciously expected stimuli.
Looping A-Habits
Looping A-habits do not need to be combined in parallel with non-looping action habits. They can be started and loop indefinitely as long as their trigger stimuli occur. Walking works this way. Also action habits to keep a limb stationary works this way. Looping action habits can be combined with other looping action habits provided their frequency is a multiple of each other.
Novel Binons
Do only the attended to novel stimuli / binons get kept? Do we have to attend to a stimulus before it can be recognized again? If so then the novel combinations created by STMs need to be flagged as temporary and only become truly novel when attended to. How does this fit with the 19th Sept and 4th Oct 2013 ideas? Is this the idea of triggered and then fired, a two-step process to become permanent / remembered?
6th October 2013 Trigger then Fire
All binons go through the trigger then fire sequence. One source binon triggers a target binon and then the second source binon fires the target binon. The same as the event and condition on a transition on a UML state machine diagram. It's an If event and condition Then ... process. Except the condition is another event. What I need for binons is to 1st place them in a novel state when their two source binons occur. As before, a novel binon cannot be combined with any other. Then if and when attention is paid to the novel binon it becomes interesting. And then when it is re-experience consciously (attention paid to it again) it becomes familiar. But, can interesting stimuli be combined with other interesting or familiar stimuli? I will keep the rule at this point that the two source binons must both be familiar.
Attention
Carry on from 4th Oct 2013. While performing a task, novel stimuli from unattended senses and/or sensors sometimes do not attract attention. This is because there are multiple subconscious action habits being performed that have expectations on these senses and / or sensors. This somehow inhibits novel stimuli from these senses and/or sensors being formed or from interrupting attention. This could be due to inhibition of the expected stimuli that may be source binons for novel stimuli.
16th and 17th October 2013 Action Habits
I need to refine the steps from the 5th October 2013.
3.0 Set the attended to stimulus to zero, goal and expected stimulus set if have expectation - doing A-Habit.
3. If practicing an action habit attention will be focused on an expected stimulus. This stimulus will be the goal stimulus of the consciously active action habit or a stimulus further down the hierarchy of actons that comprise the action habit.
- 3.1 If we get the expected stimulus then
- 3.1.1 If down in the middle of the action habit then continue doing it and set the expected stimulus as the attended to stimulus.
- 3.1.2 Else we have the goal stimulus and the action habit becomes learnt, update it so not interested in being redone. If there is a previous learnt action habit then combine this one with the previous one in a hierarchy of actons. It will also be combined with the subconscious non-looping ones that were being done in parallel. Now that the action habit is learnt and the goal is familiar attend to whatever is the most interesting stimulus. This will do steps 4 and 5.
- 3.2 Else it will only be distracted by a stimulus within the attention focus area that is different from the expected one. So get this unexpected stimulus and create a new action habit with this as the goal. Make this goal the attended to stimulus. This will skip steps 4 and 5. A pleasant or unpleasant stimulus will distract the attention from completing an action habit that is being practiced with a redo interest based on achieving a novel goal but not a pleasant goal.
- End if
End if
4. If don't have an attended to stimulus (not practicing an action habit) then the most interesting stimulus attracts attention. Find it and it becomes the attended to stimulus. This is the biggest combination / longest sequence that is interesting.
- 4.1 If there are no interesting stimuli then a novel stimulus attracts attention.
- 4.2 Else if no novel stimuli then a familiar stimulus attracts attention. This is the biggest combination / longest sequence that is caused by a change that is familiar. These stimuli are the ones created in the STMs and do not include sequences that switch between focus areas of attention such as switches between senses.
- End if
End if
5. If have a trigger stimulus (and have done any action) but no expected goal stimulus then
Create a new action habit with the attended to stimulus as the goal.
End if
6. If there are any action habits whose trigger stimulus is the one to which attention is focused it may be started. If there is a current action habit being practiced it will continue unless a more interesting action habit is found in the steps below.
- 6.1 If pleasant and unpleasant goal stimuli exist then the most recent action habit with a pleasant goal will be started and provided it is learnt will be done subconsciously. Its goal will be the expected goal stimulus.
- 6.2 Else if there are action-habits that have redo interest then start the most recent one.
- 6.3 Else if there is no action habits with a redo interest then pay attention to the goal stimulus of the most recent action habit and repeat at step 6 with the goal stimulus as though it was the trigger. This is thinking of the goal by traversing the action habits for this stimulus as the trigger. This repeats until we come across an action habit that has a redo interest or an expected pleasant goal stimulus is encountered. There will be a limit on this looping to begin with. Some other criterion is required to stop this thinking.
End if
7. Else set the attended to stimulus as the trigger, perform no action and zero out the expected goal stimulus.
End if
18th October 2013 Inhibiting Stimuli
I'm quite sure the right approach for focusing the attention is to inhibit all the expected stimuli of all the active action habits, conscious and subconscious, such that should they be perceived they are not combined with any other familiar stimuli. Thus any non-inhibited familiar stimuli are combined and novel ones can occur, because you can't inhibit stimuli you have never before perceived. This allows novel and interesting stimuli to attract attention, especially when the conscious action habit completes by getting its goal stimulus.
19th October 2013 Repeating action habits
I've got inhibition of expected stimuli working but I am not stopping the counting of repeated sequences when attention is not being focused on the stimuli. I'm presuming that the counting of repeated stimuli should be inhibited by the execution of subconscious action habits that are running in parallel with the consciously active one. But what starts the action habits running? I have always thought that all action habits are started consciously due to a desire to do them. The ones that are learnt are then done subconsciously while the one that has a desired goal is performed consciously and it directs attention. But what is the desired goal that triggers the start of the action habits that are done subconsciously? This question particularly applies to those that are being performed to disregard repeated stimuli and ones to hold limbs in steady positions, such as holding one’s head erect.
It is possible that the action habits that are being done to obtain a desired result include, in parallel, all the other action habits that are done subconsciously to inhibit repeated sequences of stimuli. Or do learnt action habits automatically start as long as their trigger stimulus has occurred, even if it has not been consciously paid attention to? I've got the recognition part not counting a repeating atomic stimulus such as AAAAAA because of habituation. But if the repeat is of a sequence such as ABABABAB etc. then this is counted. There is an inconsistency here. Ideally there should be just the one mechanism involved in habituation of a sequence, whether it is composed of atomic stimuli or compound ones.
I think I have it. S-Habits also inhibit their expected stimuli. When an S-Habit binon receives its 1st source binon it is expecting its second source binon. It then inhibits the second stimulus binon such that should it occur it is not combined with any others. A binon inhibits itself so that when it repeats it ignores the next input which gives habituation. A sequence inhibits its second part that it is expecting. This means that action habits only have to inhibit inter-sense sequences.
27th Oct 2013 Actons
Actons that play together, stay together.
This is a variation on the famous saying, "neurons that fire together, wire together". It's basically all about the co-incidence of the events. And this is what I have to do for sequentially repeating patterns of action habits even if they contain the "no-action" and just contain the action of changing attention to the goal stimulus.
October 2013 LinkedIn Discussions
I would suggest that every perception is always multi-modal (multi-sense). It becomes most evident when a familiar experience occurs and stimuli from one of your senses are missing.
Would you notice it if you moved the paint roller on the wall but didn't hear the little speckley noise it makes?
Would you notice it if you heard a car passing you on the street and didn't see it?
Would you notice it if someone spoke to you but you didn't see their lips moving?
Would you notice it if you typed on your keyboard, saw it, heard the key taps but did not feel them on your fingertips?
Would you notice it if the air-conditioner stopped making its background noise?
As for the bandwidth, it is very high at the sensor end. But at the conscious end it can be represented as a single neuron because of the power of a hierarchy. Then your attention can be focused at any point in that hierarchy. You can focus on a single itch on a point on your skin or on the holistic multi-modal experience at a point in time at the top of the hierarchy.
Hi Kartikeyan, since you were wondering how I fund my Strong AI / AGI research, here are the details. I teach Courses 218 User and Systems Requirements for Software Development, Course 447 Introduction to Modeling for Business Analysis and 1801 Modern Object Oriented Design for Learning Tree International. I am also the author of course 447 and get a small royalty stream from that. Teaching keeps me busy about 12 to 15 weeks out of the year. I also do consulting projects in business and systems analysis. This keeps me busy for about 15 weeks in the year. The rest of the time I do my AI research for my company. All the money I earn comes through my company. My company then claims a Canadian Government Scientific Research and Experimental Development tax credit for the research I do. This brings in about a quarter of my income.
All my research is done on my laptop PC.
I am a member of AAAI, ISAB, CogSci and regularly attend their conferences.
I started attending IJCAI conferences in 1973 but became disillusioned with their lack of interest in Strong AI. I then spent more time attending CogSci conferences and reading a lot more of that kind of material. I now read all manner of books in Cog Sci, AI and even neuroscience to get ideas of how the processes of learning and thinking should function.
Right now I am working on learning / practicing / building and then performing subconsciously, the hierarchical action habits for recognizing Morse code. There are lots of other discoveries I have made using a binon network. Binons are described on my web site: www.adaptroninc.com
I wish you all the best in your AI career and hope you have as much fun as I am having.
It's up to you as to how much "experience" you wish to put into your Strong AI at design time before it starts operating. By the word "experience" I mean the data collected by the senses and it does not include algorithms, methods, processes, heuristics, or procedures. It is true that "humans are born with lots of pre-designed algorithms that have been configured by evolution". My research approach is to discover these algorithms for learning and thinking. And it also includes inventing the empty data structures that the stimuli are going to be stored in. I expect Adaptron to learn everything about its environment from its experiences. So all the data / stimuli are collected at run time, processed by the algorithms and stored in the data structures.
Perceptra is a good example of how this works for pattern recognition
Hi Juango, I have no ambition to ever pass the Turing test. If I am able to reach the level of learning and behaviour of a rat I would be happy.
Hi Csaba, no criticism taken. I only decided recently to start publishing my research. I only work on it part time and what I am trying to do is not trivial. It's also not about programming any specific abilities to respond to specific stimuli and perform any specific actions in advance. Everything it recognizes and all motor activity must be learnt. And it all has to be driven by the desire to obtain novel experiences. This means the goal is the pursuit of change and new experiences and avoidance of repeated boring experiences.
It may be another two years before I get around to publishing my next paper. In the meantime, I too look forward to seeing how my ideas evolve. :)
12th Nov 2013 Unexpected Sequences
On the 6th Oct 2013 I thought about trigger then fire. Now I am thinking about how this applies to sequences because a sequence can be recognized as novel but does not become interesting until attention is paid to it. This is especially true of short sequence such as the sound sequence "twang". One does not have the speed of attention shifting to start to notice the start or middle of this sound sequence. Short-term memory has already created the sequence S-Habit. Attention is paid to the sequence as a single symbolic object type. Short-term memory keeps on throwing away novel sequences when repeats occur. Also the sequences are inhibited by A-Habits. But when attention is paid to the sense repeats start to be counted. The key aspect of A-Habits is they are being done to inhibit the expected sequences such that the unexpected ones attract attention. And this is happening to sequences so the inhibition of a sequence must remain in place while the sequence is happening. Thus inhibition has duration.
Coincidental sequences
This brings up the thoughts about how to deal with coincidental sequences. Do two sequences need to start at the same instance, end at the same instance or have at least some overlap in time to be considered coincidental versus in series? I would tend to start with the hypothesis that they need to overlap in time to be combined as coincidental (in parallel).
Action habits
To combine action habits into sequences the following changes are needed to the algorithm described on 16th Oct 2013.
3.0 Set the attended to stimulus to zero. The goal and expected stimuli will be set if have an expectation - doing A-Habit.
3. If practicing an action habit, attention will be focused on an expected stimulus. This stimulus will be the goal stimulus of the consciously active action habit or a stimulus further down the hierarchy of actons that comprise the action habit.
- 3.1 If we get the expected stimulus then
- 3.1.1 If down in the middle of the action habit then continue doing it and set the expected stimulus as the attended to stimulus.
- 3.1.2 Else we have the goal stimulus and the action habit becomes learnt, update it so not interested in being redone.
- 3.1.2.1 If there is a previous learnt action habit then combine this one with the previous one in a hierarchy of actons. It will also be combined with the subconscious non-looping ones that were being done in parallel.
- The learnt action habit now becomes the previous one for combining purposes.
- Now that the action habit is learnt and the goal is familiar attend to whatever is the most interesting stimulus. Zero out the trigger stimulus and the expected one. This will do steps 4 and 5.
- 3.2 Else it will only be distracted by a stimulus within the attention focus area that is different from the expected one. So get this unexpected stimulus and create a new action habit with this as the goal. Make this goal the attended to stimulus. This will skip steps 4 and 5. A pleasant or unpleasant stimulus will distract the attention from completing an action habit that is being practiced with a redo interest based on achieving a novel goal but not a pleasant goal.
- End if
End if
4. If don't have an attended to stimulus (not practicing an action habit) then the most interesting stimulus attracts attention. Find it and it becomes the attended to stimulus. This is the biggest combination / longest sequence that is interesting.
- 4.1 If there are no interesting stimuli then a novel stimulus attracts attention.
- 4.2 Else if no novel stimuli then a familiar stimulus attracts attention. This is the biggest combination / longest sequence that is caused by a change that is familiar. These stimuli are the ones created in the STMs and do not include sequences that switch between focus areas of attention such as switches between senses.
- End if
End if
5. If have a trigger stimulus which was the one attended to the previous time through this process (and have done any action) but no expected goal stimulus then
Create a new action habit with the attended to stimulus as the goal.
End if
6. If there are any known action habits whose trigger stimulus is the same as the attended to one (has the focus of attention), it may be started. If there is a current action habit being practiced it will continue unless a more interesting action habit is found in the steps below.
- 6.1 If pleasant and unpleasant goal stimuli exist then the most recent action habit with a pleasant goal will be started and provided it is learnt will be done subconsciously. Its goal will be the expected goal stimulus.
- 6.2 Else if there are action-habits that have redo interest then start the most recent one.
- 6.3 Else if there is no action habits with a redo interest then pay attention to the goal stimulus of the most recent action habit and repeat at step 6 with the goal stimulus as though it was the trigger. This is thinking of the goal by traversing the action habits for this stimulus as the trigger. This repeats until we come across an action habit that has a redo interest or an expected pleasant goal stimulus is encountered. There will be a limit on this looping to begin with. Some other criterion is required to stop this thinking.
- End if
7. Else perform no action and zero out the expected goal stimulus.
End if
8. Set the attended to stimulus as the trigger stimulus for step 5.
9. If the goal stimulus of the previous action habit is not the same as the attended to stimulus then reset the previous action habit (we can't combine the previous one because attention was switched).
14th Nov 2013 Partial Match
One of the solutions I came up with yesterday (see Test results from yesterday) to get the combined action habit started was to allow a partial match of an attended to stimulus to a stimulus that has a known action habit in step 6 above. This solution also is based on the idea that only subconsciously executing action habits inhibit their expected stimuli. The goal stimulus of a conscious action habit does not need to be inhibited because it will be focused on. This results in the S-Habit that includes the goal stimulus being formed at the same time the combined action habit is formed. If the S-Habit is interesting then it is attended to. It will not have any action habits, having been novel and now interesting but its second sequential part may have an action habit worth redoing.
16th Nov 2013 Practice
In step 6.1 we are starting a learnt action habit and doing it subconsciously. The desired and expected goal stimulus is thought about before starting but is then forgotten, until reaching the goal reminds one of it. In 6.2 the action habit to redo is done consciously. It is concentrated on. Attention is paid to the stimuli involved until the expected goal stimulus is reached. In 6.3 two learnt action habits are thought about that could work in series to obtain a desired and expected goal stimulus. Practicing them in sequence as in step 6.2 will combine the two action habits. Then there is the modification of a learnt sequence by replacing part of it by a more desirable sequence. And there is the addition of another action in parallel with one being practiced. Adding in parallel and replacing parts must be done during practice if it is to remain part of the new action habit.
17th Nov 2013 Multiple Goals
If we have an action habit T A1 G1 (T = Trigger, A1 = Action1, G1 = Goal1) and then:
A/ get T A1 G2 - more recent - new expected goal or
B/ get T A2 G1 - new way to reach the original goal.
If the action is pay attention then get a lot of the first case (A/) because T An G1, T An G2, T An G3 etc. where An = do nothing - just pay attention to the where part of the goal.
When get T A1 G learnt and G A2 H also learnt create T A3 H (H is a stimulus - goal) where A3 = A1 G A2
An acton sent to a device tells it its set point?
18th Nov 2013 Actions
If a source acton contains two target actons and these are symbolic then they represent a change in the desired device from the 1st symbolic act to the 2nd symbolic act. If this goes all the way down a tree of such actons then the final ones must tell the device to perform an act that it knows symbolically. Does this symbolic act represent a set point which the device must maintain? This implies the device has a built in intelligence / control algorithm to maintain this "position". It also means it has a way of monitoring / sensing its "position". But what about a device that does not have this built-in intelligence? It must be given a graduated value and the control intelligence must be in the acton hierarchy. The lowest level act must be / provide graduated values. And the lowest level acton must contain two of these acts separated by a feedback stimulus that must be matched before the device is sent the 2nd act.
23rd Nov 2013 States
Stimulus = event = pattern of change
Device symbolic command = action
State = acton
potentiation - states - nested
Parallel states waiting for possible stimuli
S, A --> many possible next stimuli
Activate the whole network - all actons each state / acton waiting for a particular stimulus, when it is detected activate another or the same network. Automatically deactivate if don't get the stimulus? Acton waiting for a stimulus - by activating it you are making it "pay attention" subconsciously for the stimulus - so do action followed by do focus of attention - equivalent to do action and activate the appropriate acton.
Only one stimulus will cause change of state / acton to another acton. It's the one the acton is waiting for.
But to get 2 actons activated in parallel a transition must be able to activate 2 actons. One stimulus recognized 2 actions? Performed and 2 new actons activated in parallel. Or a cascade of potentiated actons.
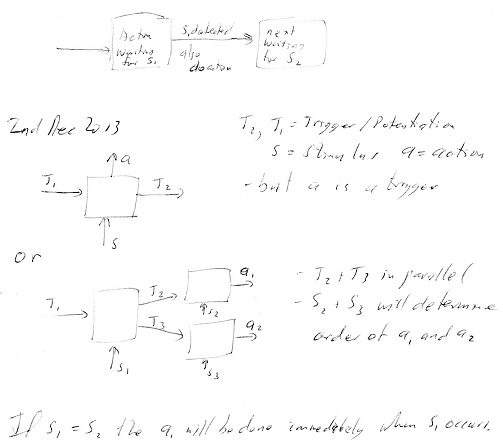
17th Dec 2013 Sequence Recognition
If we were to disregard the fact that an acton triggers two sub-actons they could be thought of as sequence binons. A sequence binon is activated (triggered) when its first source binon is recognized and then fires when it recognizes its second source binon. When it fires it would activate all of its target sequence binons. If no second source binon is recognized in the next cycle then the sequence binon loses its activation. This would be equivalent to an acton with one or more sub-actons that are activated when it fires. Lowest level actons fire the acts of devices. The equivalent sequence binon would have a single act of a device as its target. The lowest level sequence binons would have either single property binons or P-Habit combinations of property binons as source binons. But higher-level sequence binons would have lower level sequence binons as source binons. Because a sequence binon could have any number of target binons multiple target sequence binons get activated in parallel when it fires.